

Application de l’analytique des données aux sondages auprès des employés avec Python
Python est un langage de programmation de pointe, gratuit et à source ouverte. Pour les auditeurs qui ont compris que savoir coder est l’une des compétences requises à l’ère du numérique, Python est peut-être le langage le plus facile à apprendre. Les auditeurs qui ont l’habitude de créer des formules dans Excel ne devraient avoir aucune difficulté à tirer parti des modules généralistes dans les bibliothèques Python pour exécuter rapidement et de manière cohérente n’importe quelle fonction financière, mathématique, statistique ou logique dans Excel. Les principaux avantages de Python incluent notamment l’absence de limitation de la taille des fichiers et le fait qu’après la création d’un programme, le même ensemble complexe de fonctions peut être rapidement appliqué à toutes les cellules d’un fichier sans copier-coller supplémentaire. Certains logiciels d’analyse de données disponibles dans le commerce et couramment utilisés par les auditeurs, comme IDEA et ACL, intègrent désormais Python, et un auditeur interne possédant des compétences intermédiaires en Python peut appliquer des techniques analytiques des données sophistiquées ou même des algorithmes d’apprentissage automatique2 qui complètent les capacités préexistantes du logiciel. Les auditeurs dont les compétences en programmation sont limitées peuvent en faire autant en collaborant avec un collègue scientifique des données ou programmeur.
On peut donc se demander s’il existe ou non une fonction analytique des données dans une bibliothèque Python qui permettrait de trouver des associations entre des questions fondées sur un attribut (par exemple supérieur ou inférieur à la moyenne) dont le caractère, en tant qu’attribut plutôt que valeur, est intrinsèquement flou. Il existe en effet une telle fonction analytique des données, appelée fonction de Gini. Elle est utilisée dans l’apprentissage automatique pour créer des arbres de décision qui prédisent quand un résultat est susceptible de se produire sur la base du modèle des entrées. Cette fonction peut par exemple servir à prédire la fraude, les créances douteuses ou certains problèmes médicaux comme le diabète. Toutefois, l’analyse des données d’un sondage ne vise pas à prédire un résultat : il s’agit simplement de savoir si les réponses sont associées en fonction du fait que leurs scores ont tendance ou non à varier de concert au-dessus et en dessous de la moyenne.
À cette fin, j’ai développé un programme Python qui emprunte l’algorithme de Gini à l’apprentissage automatique pour le mettre en œuvre sans arbre de décision. Au lieu de créer un arbre de décision, le programme applique une fonction de Gini aux paires de scores de réponse agrégés des questions du sondage. Cela permet d’obtenir un grand tableau contenant l’indice de Gini pour chaque paire de questions, dont une partie est présentée à la figure 2.
Figure 2 – Exemple de tableau contenant l’indice de Gini pour des paires de questions
|
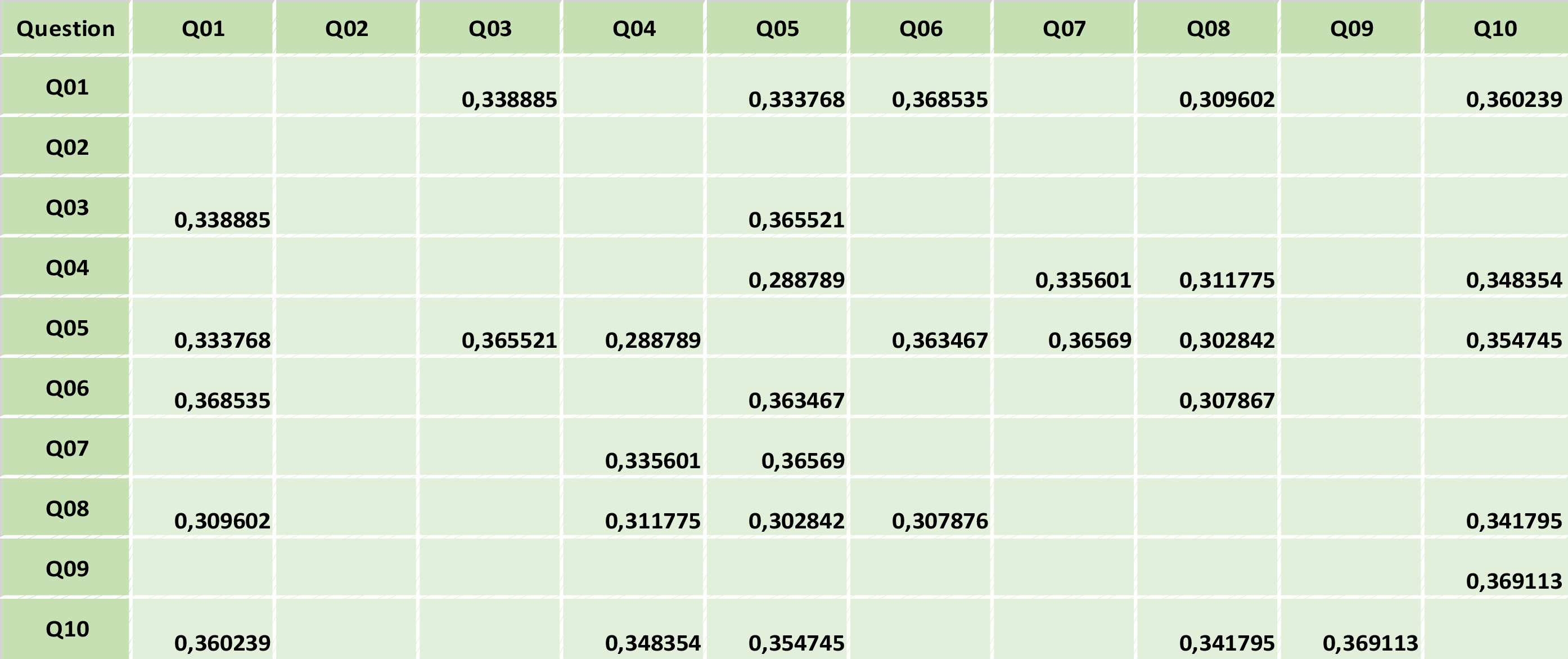
La discussion qui suit sur l’indice de Gini fait référence à deux types de scores agrégés qu’il est important de distinguer. Le score de réponse agrégé d’une question correspond au score d’un seul groupe sous-culturel pour cette question, tandis que le score de réponse agrégé moyen décrit la réponse moyenne de tous les groupes sous-culturels à une question. Chaque référence à un score « supérieur à la moyenne » ou « inférieur à la moyenne » désigne le score de réponse agrégé moyen pour une question dans tous les groupes sous-culturels de l’organisation.
Que signifient les indices de Gini dans le tableau? Examinons la configuration des points dans la figure 3. Chaque point représente le score de réponse agrégé d’un groupe pour la paire de questions indiquée. (Les combinaisons de réponses possibles sont supérieur-inférieur, supérieur-supérieur, inférieur-inférieur et inférieur-supérieur au score agrégé moyen.) On peut constater à l’œil nu qu’il existe une association apparente entre les réponses aux deux questions. L’indice de Gini pour la paire de questions avec cette configuration particulière de réponses agrégées est de 0,37 et cette configuration de points illustre le cas limitant, c’est-à-dire que l’indice de Gini pour toute paire de questions doit être inférieur ou égal à 0,37 pour que les questions réussissent le test d’association. Si l’une des réponses agrégées associées devait changer de sorte qu’un seul des points se déplace horizontalement (par exemple si l’un des sept points Q1-supérieur/Q2-supérieur devenait un point Q1-supérieur/Q2-inférieur), l’indice de Gini augmenterait et le test échouerait.
Figure 3 – Illustration d’une association positive dans une matrice de Gini deux par deux
|
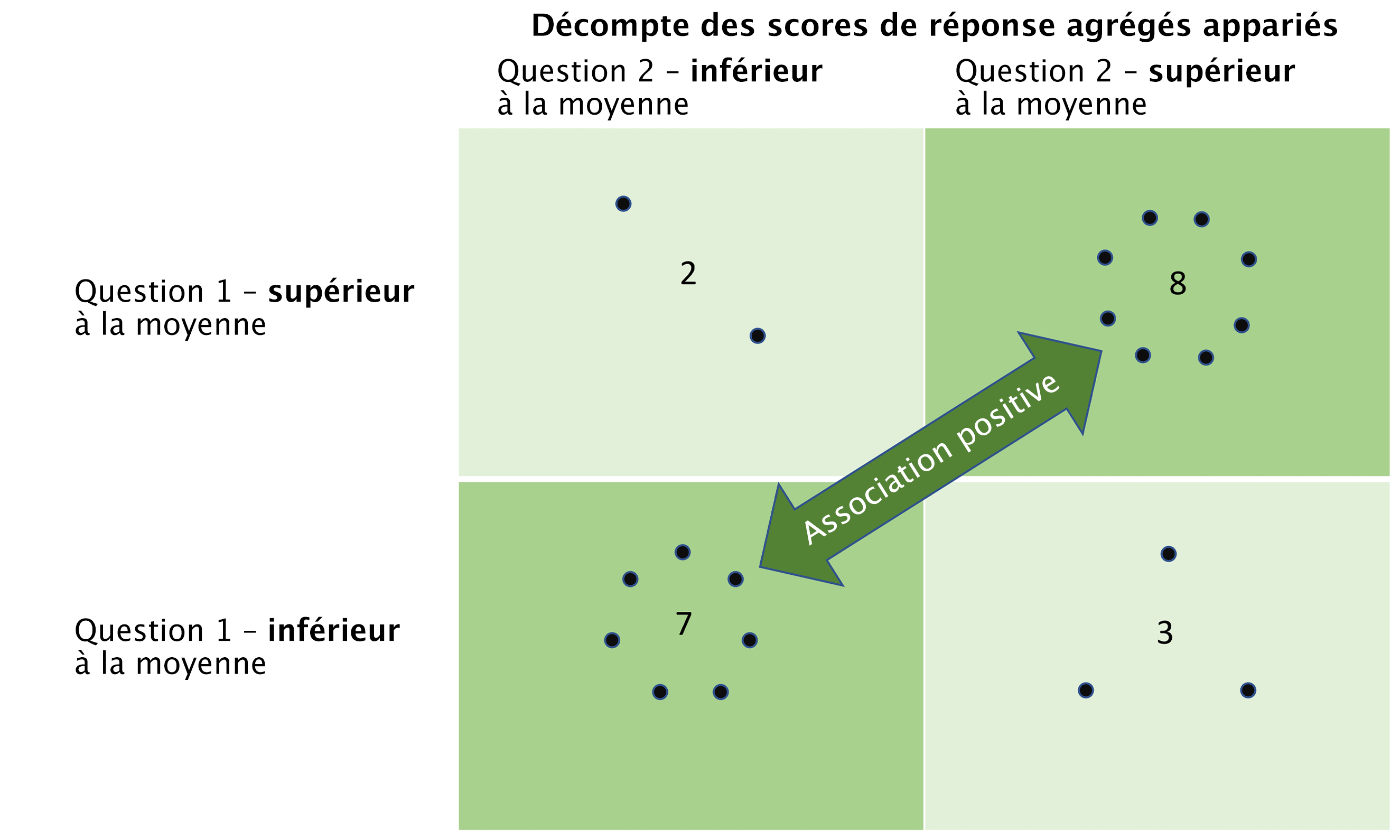
L’indice de Gini est une mesure de la « pureté » d’un échantillon – la pureté étant, dans le contexte de deux attributs, une mesure de l’homogénéité de la distribution des attributs dans l’échantillon. Ainsi, si deux attributs comme le score agrégé supérieur à la moyenne et le score agrégé inférieur à la moyenne sont uniformément répartis dans un échantillon de deux questions (c’est-à-dire si chaque carré de la figure 3 contient cinq points), la pureté de Gini serait de 0,5 (la valeur maximale). En revanche, si l’échantillon ne contient que des ensembles couplés de scores appariés – par exemple si chaque score supérieur à la moyenne pour la première question est apparié à un score supérieur à la moyenne pour la seconde question et qu’il en va de même pour les scores inférieurs à la moyenne – il s’agirait d’une association positive à 100 % et l’indice de Gini serait de 0.
Contrairement aux mesures statistiques de la corrélation, l’indice de Gini ne nécessite pas d’hypothèses sur la relation mathématique ou la distribution normale des réponses. Il peut être considéré comme une mesure non métrique de l’association, en tant qu’outil programmatique permettant d’identifier ce qu’une personne conclurait en observant la distribution des réponses dans une matrice deux par deux. En soi, l’indice de Gini ne fournit pas suffisamment d’informations pour tirer des conclusions susceptibles de modifier le déroulement d’un audit. Après identification des réponses associées, il faut procéder à l’analyse en appliquant des filtres permettant de déterminer quelles réponses aux questions du sondage présentent le plus d’intérêt.
L’un des filtres les plus importants est la variabilité des réponses à une question. La variabilité signifie que certaines parties de l’organisation sont plus performantes que d’autres, et la comparaison entre la dynamique de ces sous-cultures organisationnelles pendant l’audit peut conduire à des recommandations sur les mesures d’amélioration qui s’imposent.
Un deuxième filtre important est ce que l’on pourrait appeler les « références », c’est-à-dire le nombre d’autres questions du sondage auxquelles une question donnée est associée. Les références donnent une indication du nombre d’autres réponses qui pourraient être améliorées simplement en améliorant la réponse à une question qui a plusieurs références.
Quelques exemples d’analytique appliquée
Les filtres font toute la différence entre l’analyse, qui résume les scores de réponse sans fournir d’informations suffisantes pour orienter la prise de mesures correctives, et l’analytique, qui met en évidence les questions prioritaires, les enjeux au sein de groupes d’employés spécifiques et les associations entre les différents problèmes. Ces associations sont particulièrement intéressantes pour les auditeurs internes et les auditeurs de performance car elles fournissent une base pour l’analyse des causes profondes et l’appui des recommandations.
Prenons l’exemple d’une analyse qui identifie l’excès d’étapes d’approbation comme un enjeu organisationnel. À première vue, la recommandation naturelle serait de résoudre le problème en réduisant les paliers de direction et en déléguant vers le bas certains pouvoirs. Toutefois, l’analytique peut révéler que le problème des étapes d’approbation est associé à des priorités en constante évolution, à l’absence d’attentes claires et à la confusion concernant la vision, la mission et les objectifs, c’est-à-dire qu’il pourrait être mieux résolu en améliorant le leadership et la communication.
Pour prendre un autre exemple, les sondages auprès des employés leur demandent souvent d’indiquer s’ils considèrent que leur organisation est un endroit où il fait bon travailler. L’analyse peut certes révéler un score agrégé faible pour cette question, ce qui est source d’inquiétude, mais si l’on n’applique pas l’analytique, il n’est pas toujours évident de savoir quelle mesure corrective pourrait être prise. L’analytique peut révéler des éléments associés, par exemple le manque de reconnaissance, l’insuffisance des ressources et l’exposition au harcèlement, qui justifient un suivi.
2 L’apprentissage automatique est une forme d’intelligence artificielle axée sur la création d’applications qui apprennent à partir de données, si bien que les décisions et les prédictions s’améliorent à mesure que de nouvelles données sont disponibles.
Page 2 de 3
